
ML Unsupervised Learning: Chicago Public Schools
In this end-to-end Data Science project, I gathered and analyzed data on Chicago Public Schools. By using Machine Learning clustering algorithms, I was able to group schools by their similarity on a variety of effectiveness measures including instruction quality, family involvement and others.
See full analysis notebook: Jupyter Notebook | GitHub
Interact with the data on Tableau Public: Maps | Effectiveness Metrics
Download PDF
1. Introduction
Before we describe the motivation and goals for the project, we need to define a few Machine Learning concepts:
Supervised vs Unsupervised learning
In supervised learning, the data that we are trying to model is labelled, meaning that it contains "ground truth". For example, if we are modeling describing different characteristics of dog breeds (such as adult weight, coat type, etc.), the initial data might contain information for individual dogs, along with the actual breed for each dog (the label). The model would learn relationships between those characteristics and the breeds and later be able to predict the appropriate breed for new unlabelled samples. In unsupervised learning, there are no labels (no ground truth). We simply have the characteristics and the models merely find patterns within the given data.Clustering
This is an example of unsupervised learning where the learning algorithm tries to find groups or clusters of samples from the given data. Back to the dog breed example, one could have a dataset of characteristics for individual dogs without the name of the corresponding breed. A clustering algorithm would learn patterns from the data and come up with groups of dogs that are similar to each other. In this case, the algorithm would not have access to any information on names of characteristics of actual breeds but would simply indicate which dogs can be grouped together.

Click here to interact with the maps on Tableau Public
Motivation
The overarching motivation behind this project was to work on an end-to-end Data Science project that would span the entire process: data acquisition, data cleaning, exploratory data analysis, modeling through Statistics or Machine Learning algorithms and finally presentation through visualization.

As part of my on-going independent Data Science studies, there are a few specific aspects of the DS pipeline where I wanted gain experience by working on this project:
Data acquisition
There are untold ways to gather data. In this case, I developed web-scrapers using Python (code available on the GitHub repository for the project) to gather survey and income data. Although there are many interesting datasets available online, such as on Kaggle.com, I wanted to gain experience on gathering real-world data.Unsupervised Machine Learning models
There are a variety of approaches to grouping (clustering) data, each with its own advantages and disadvantages. I wanted to gain hands-on experience with some of the most popular approaches. Also, there is a particular problem in unsupervised learning, which is the difficulty of evaluating model performance. Because the data is unlabelled, there is no ground truth to which we can compare a model, which also means its particularly challenging to compare models to each other. In this project, I consider several ways that we can attempt to solve this issue and get evaluation metrics that we can trust.Presentation
This is an important and often-overlooked aspect of the Data Science pipeline, particularly becasue the modelling step is usually considered more intriguing and attractive. I wanted to practice presenting the results from the rest of the analysis in a way that is visually intuitive and interactive. I used Tableau to build the graphics.
Goals
In this analysis we will try to answer the following questions:
Do the Chicago Public Schools fall into clusters according to this dataset?
If so, how well defined are these clusters?
If not, is it possible to partition the data in a way that is informative?
What information separates the clusters/partitions?
How can the results provided by this analysis be used for action?
2. Dataset
School data
The school survey information comes from https://5-essentials.org/cps/5e/2018/ and it contains 5 different ratings per school (values 0-100):
ambitious instruction
collaborative teachers
effective leaders
involved families
supportive environment
We also obtained the name and full address for each school.
Some important notes on the Data Acquisition process:
The web-crawler we developed inserted -1 for missing values. We decided to discard the instances with more than 2 missing values, which totalled 15 school
Schools that didn't have numbers for any of the categories were skipped altogether by the web-crawler
There was one mistake in the data: the ZIP code for George Washington Carver Military Academy HS is supposed to be 60827, not 60627.
Here are the first 5 entries in that dataset:

Income data

The income data was obtained from this website: https://www.zipdatamaps.com/zipcodes-chicago-il. It contains the median household income for each zip code.
We found 3 rows (out of 68) with missing or invalid income information. We decided to insert the median of all ZIP code incomes into those rows, but for a future analysis one may want to find the actual values.
The survey features contained values ranging from 0 - 100, so we scaled the income to a similar range. Clustering algorithms often measure the distance between data points, so its important that all features occupy a similar range.
3. Exploration
The dataset contains a total of 6 columns (5 features containing survey information + 1 containing income).
Because it's impossible to visualize a 6-dimensional space, we plotted the features pair-wise to see if we could find any outstanding relationships or patterns. The diagonal consists of histograms showcasing the distribution of values for each feature.

From the histograms on the diagonal of the chart, we can see that there are no values below 0 or above 100 for any of the features.
Although it's impossible to draw conclusions on the data's cluster structure from looking at 1 or 2 variables at a time, we need to note that there are no clear separations that we can establish visually just yet.
4. Model Selection
Scikit-Learn is a Python library that offers implementations for a variety of clustering algorithms. Each one of these has their own hyper-parameters that can be tweaked and their own 'preferences' as to what types of clusters they are able to distinguish. I will provide a short description for each of these algorithms.
Model Evaluation
We'll also evaluate how each algorithm performs under different hyper-parameter values. Because we're dealing with unsupervised learning, we do not have a 'ground truth' to which we can compare the cluster assignments. However, we can use the silhouette coefficient, which measure how close each instance is to the other instances of their own cluster, compared to the instances in the next closest cluster. We can interpret the silhouette coefficient as follows:
A sample's silhouette coefficient of 1 means it is extremely close to the other instances in its cluster and extremely far from the instances in the next closest cluster, i.e. it is perfectly assigned.
A silhouette coefficient of 0 means the sample sits on the border between the two clusters.
A negative coefficient indicates that the sample has been mis-assigned.
Silhouette coefficients can be visualized in a silhouette diagram, where samples are grouped by cluster and their silhouette coefficients plotted horizontally. Ideally, we'd like all clusters to cross the average silhouette coefficient (the silhouette score) and contain as few negative values as possible.
In addition to silhouette diagrams, we can do something much less formal: visualize the cluster assignments on the features themselves. Because we cannot visualize 6 dimensions at a time, we'll just use 3 pairs of features and be content for now. These visualizations should not be used to draw conclusions but merely to partially observe the results of the algorithms.
Once we narrow down our options, we'll compute a 3-D projection of the dataset using t-SNE. Although we will lose all concept of units at that point, we'll be able to visualize the results in a more informative way.
K-Means
Probably the most popular of the bunch, K-Means groups data points using distances. The process amounts to these basic steps:
Initialization: cluster centroids get to random instances. In sklearn, the default initialization is "KMeans++", which places the centroids far from each other.
Instances get assigned to their closest centroids
Update centroids based on the instances that were assigned to them Repeat steps 2 and 3 until centroids stop moving.
In K-Means, we need to tell the algorithm how many clusters we'd like to see. We can evaluate different numbers k of clusters with silhouette diagrams. This algorithm expects clusters to be of globular (spherical) shapes and similar sizes. It also assigns every instance to a cluster, including 'noise' points.
Below are the silhouette diagrams for K-Means for 2 to 9 clusters.

The red dotted lines represent the silhouette scores, which are the average of all silhouette coefficients. This was highest when the algorithm found 2 clusters: 0.483.
All other numbers of clusters produced some negative silhouette coefficients, which represent samples that were, on average, closer to a different cluster's instances than instances from their own cluster.
Next, we visualize the clustering obtained when assigning 2, 3 or 4 clusters through KMeans, including the cluster centroids. Again, this is a very limited visualization in 2 dimensions of a 6-dimensional dataset, so its only purpose is to get some intuition behind the model's output.

DBSCAN (Density-Based Spatial Clustering of Applications with Noise)
From sklearn's documentation: DBSCAN finds core samples of high density and expands clusters from them. Good for data which contains clusters of similar density.
The algorithm finds core instances by determining if they have enough neighbors min_samples within a certain distance epsilon. All instances within in the epsilon-neighborhood of a core distance are assigned the same cluster. An instance that is not in the neighborhood of a core distance is an anomaly.
This algorithm works with clusters of any size and shape. The challenge when using DBSCAN is tuning the hyperparameters eps and min_samples.
In order to find a good value for epsilon, we'll first get an idea of how far the samples are from each other. We can get distance between each instance and its nearest neighbor by using the NearestNeighbors class. This is an unsupervised algorithm that computes and returns, for each instance, the distance to its closest neighbor and the index of that neighbor. We'll then sort and plot these distances.

We can see that most (almost all) of the instances are at a distance of 20 or less from their nearest neighbor. We can safely say that by setting epsilon somewhere between 16 and 21, DBSCAN will find regions of high-density and discard instances that are far away from any dense areas (anomalies). We chose 18 but this value could be changed if we decide we need to fine-tune this model.
Explore the outliers
By setting min_samples to 5, we obtained one cluster ('0') with 568 instances and 72 outliers, which were assigned -1. Although we didn't get multiple clusters, this could still be interesting information. By looking at the table below, we can see that many of this outliers had a large spread of values across the different variables. There could be other reasons why these instances are considered anomalous by the algorithm, but is subject to more analysis.


Outliers are represented in the darker blue/green color, while the clustered instances are light green.
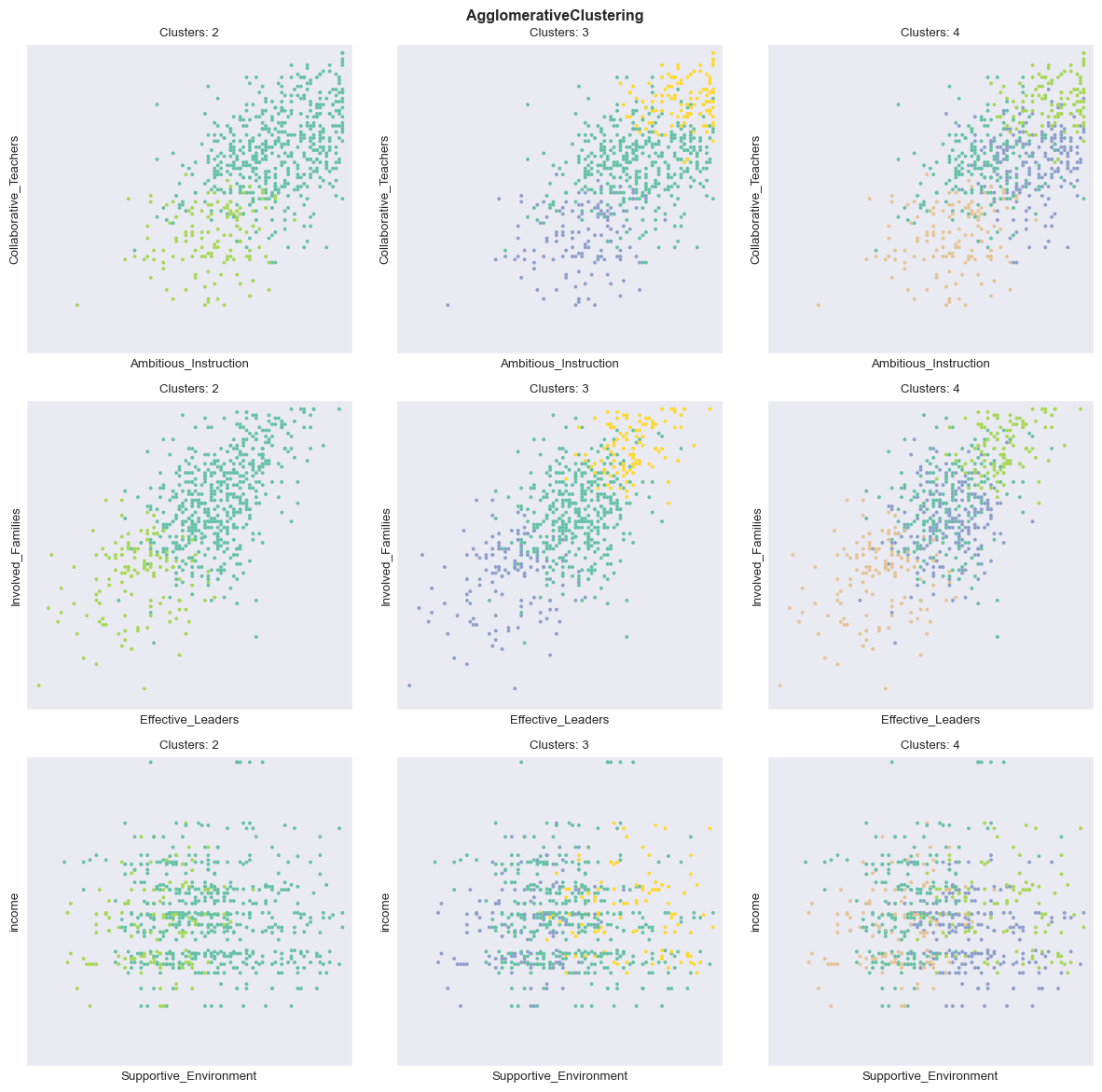
Aggloremative Clustering (aka Hierarchical Clustering)
From Hands-On Machine Learning with Scikit-Learn, Keras & Tensorflow by Aurélien Géron: A hierarchy of clusters is built from the bottom up. Think of many tiny bubbles floating on water and gradually attaching to each other until there's one big group of bubbles. A nice aspect of this algorithm is that we can visualize how it works by plotting a dendrogram. As shown below, this lets us visualize the sequential pairing, first of individual instances, then of the combinations of instances until there only few clusters and finally just one. We can then decide how many clusters we want to end up with and compare the results with the silhouette diagrams.

Dendrogram: visualization of Agglomerative/Hierarchical Clustering

All configurations lead to many mis-assigned instances, represented by the negative silhouette coefficients. We can see in the following visualization also that the clustering in all cases is suboptimal.
Mean-Shift
Just as with DBSCAN, here we consider the neighborhood of each instance:
We start with circles of radius bandwidth around all instances.
For each instance, we calculate the mean of all instances that fall within their cicle.
Move the circle so that it's centered on that mean (thus the name Mean-Shift)Repeat steps 2 and 3 until circles converge. The bandwidth that we choose initially will determine how many clusters we end up with, i.e. at how many places did the circles converge.

We chose bandwidth values that would cause the algorithm to find 3, 4 or 5 clusters:

This algorithm tends to find one large cluster and several small ones. However, it's unusable in our case because of the number of instances with negative silhouette coefficients.

Affinity propagation
The description from the *hdbscan* library documentation is succinct: Affinity Propagation is a newer clustering algorithm that uses a graph based approach to let points ‘vote’ on their preferred ‘exemplar’. The end result is a set of cluster ‘exemplars’ from which we derive clusters by essentially doing what K-Means does and assigning each point to the cluster of its nearest exemplar.
As with K-Means, this algorithm excepts clusters to be globular. A big plus is that it automatically gets the number k of clusters for us. A drawback is that is very slow.
There are not many hyper-parameters to fine-tune. We'll try different values for preference, which determines how much each instance will "want" to be come an exemplar or representative. The higher the value, the more clusters we'll get.


With preference = -330000 we obtained 2 clusters and this is the best result in terms of the silhouette score. However, it is still not the best result we've obtained so far.

Gaussian Mixtures
A Gaussian Mixture Model (GMM) starts off with the assumption that the data was produced from a number of multi-variate Gaussian (Normal) distributions. It then tries to find the parameters of those distributions, namely the means and covariate matrices. The latter give the distributions their variance along each dimension as well as the orientation, given by the covariances. Another parameter is a weight that is assigned to each distribution.
The algorithm for finding the distributions is called Expectation-Maximization. After telling the model how many clusters we'd like, these are the basic steps that EM follows:
Initialize the cluster parameters randomly
Assign each instance to a distribution, namely the one that gives it the highest probability of being produced
Update each cluster by looking at the samples it was made responsible for
In sklearn, covariance_type can be set to 'full' (it is by default), which allows the clusters to take any shape, size and orientation. This makes GM extremely flexible.

None of these models are as effective in clustering the data as others we have seen before.

5. Selected Model
The model that seems to perform best on this dataset happens to be the very first one we tried: KMeans with n_clusters=2.
Let's make one last visualization, a 3D projection our 6D dataset. The projection is done using an unsupervised algorithm called t-Distributed Stochastic Neighbor Embedding (t-SNE), which can reduce dimensionality of a dataset. As a consequence of this reduction we lose the original units, but still get an idea of which points are close together and which are far apart. We can then color each point by the label that was assigned by the model.
In addition to coloring by cluster, we made the samples on the inter-cluster border appear lighter.

Play with the graphic: https://plotly.com/~solrelami/16/
6. Conclusion
We can now answer the original questions:
Do the Chicago Public Schools fall into clusters according to this dataset? The dataset doesn't have a 'naturally' clustered structure. None of the models presented a high silhouette score, with the highest-performing model producing a score slightly less than 0.5.
If not, is it possible to partion the data in a way that is informative? Yes. KMeans provided clusters that, when analyzed by silhouette coefficients, gave us insights on some interesting differences.
What information separates the clusters/partitions? According to the last bar-plot, there are significant differences of about 30% for all variables except 'income', which is virtually the same for both clusters.
How can the results provided by this analysis be used for action? Clustering is most often used as just one step in an analytical or predictive process. As such, the cluster labels can be used as categorical features or, if the clustering algorithm supports soft clustering, we can use the predicted probabilities as a numerical feature.That being said, I do not believe that these clusters should be used for predictive modeling since, as I mentioned earlier, there doesn't seem to be a clustering structure in the first place. We can still use these results as fodder for further analysis, for example by looking at how the clusters correspond to geographical locations or any other attributes.
Cluster composition
We can visualize how the features vary between the 2 clusters. As we can see below, income doesn't change much from one to the other. However, the other 5 features are quite a bit higher in cluster 0 than cluster 1, by approximately 30%.

In the following graphic, we compare the distributions of each effectiveness metric for the two clusters. The blue cluster consistently corresponds to higher performance, on average, for all metrics.

Human vs Algorithmic clustering
It's worth noting that it's possible for people to manually label this dataset. This could be done, for example, by averaging the values across the survey features and then selecting cutoffs: 0-25, 25-50, 50-75, 75-100.
What's the difference between that approach and ours? In the human approach, we most likely need to reduce the dimensionality of the dataset and thus lose information in the process. In the example of manually selecting cutoffs for the average scores, we are in fact reducing the 5 dimensions (or 6 if we include income) to just 1: the average.
Our approach is also flexible in that we can easily add more features by incorporating new data. While this increases the dimensionality, the clustering algorithms we've used would deal with that just as well. If we end up adding too many dimensions to properly run these algorithms, we can always apply dimensionality-reduction methods such as Principal Component Analysis.